Java中的Map
Hash 算法
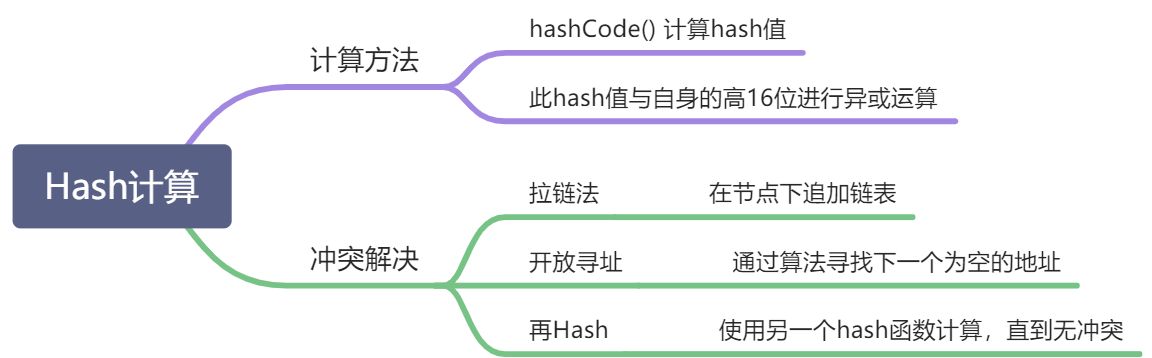
hash = (h = hashCode())^(h >>> 16)
hash 值总共 32 位,让 hash 值的高 16 位和低 16 位进行异或,目的是让高位和低位都参与之后的“与运算”,这个“与运算”计算出此元素的索引。
hashCode()是一个 native 方法,而且返回值类型是整形;实际上,该 native 方法将对象在内存中的地址作为哈希码返回,可以保证不同对象的返回值不同。
寻址算法
index = (n - 1) & hash
在 n= 2 的 n 次方的前提下,这个“与运算”和将 hash 值对 n 取模效果一样,但是执行效率高于取模。
因为数组长度 n 有限,只有 hash 的低 16 位会参与与运算,所以需要第一步让高 16 位也参与“与运算”
Map 为什么双倍扩容
1、索引计算方式为 (n - 1) & hash,当 n 为 2 的倍数时,索引会更加分散。
这里不使用数组长度取模的方式的原因
(1) & 操作效率更高
(2) 取模的方式数据冲突更高
2、数组扩容完,在对链表进行数据迁移时,不需要重新计算索引值。
新索引位置为 n+1,n 为原数组长度。
Simple is Awesome